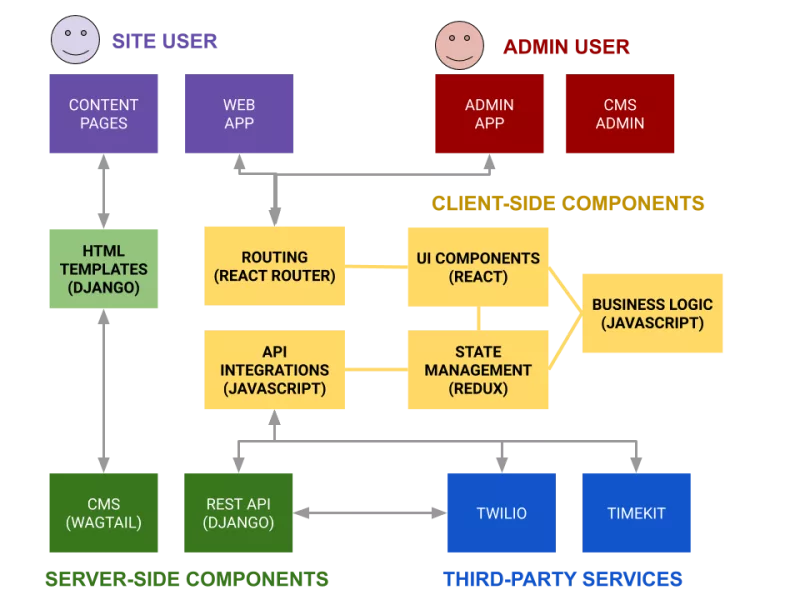
Giới Thiệu Đội Quân AI Agent "Thần Tốc"
Hệ thống Multi-Agent Systems (MAS) là một mô hình mạnh mẽ cho phép các tác nhân AI làm việc cùng nhau để giải quyết các vấn đề phức tạp, đặc biệt trong nghiên cứu và phân tích dữ liệu. Bài viết này sẽ giúp bạn hiểu rõ về multi-agent research từ góc nhìn thực tế, hướng dẫn bạn cách xây dựng một đội quân AI Agent để tự động hóa các tác vụ này một cách hiệu quả.

Trong kỷ nguyên dữ liệu bùng nổ, khả năng thu thập, xử lý và trích xuất thông tin có giá trị là một lợi thế cạnh tranh khổng lồ. Tuy nhiên, quy trình này thường tốn thời gian, công sức và đòi hỏi nhiều kỹ năng chuyên môn khác nhau. Đó là lúc các hệ thống AI đa tác nhân thể hiện sức mạnh vượt trội, cho phép chúng ta phân công các nhiệm vụ chuyên biệt cho từng agent, từ đó tăng tốc độ nghiên cứu và độ chính xác của phân tích dữ liệu lên đáng kể. Chúng ta sẽ khám phá cách các agent có thể hợp tác, giao tiếp và học hỏi lẫn nhau để đạt được mục tiêu chung.
Multi-Agent Systems Trong Nghiên Cứu và Phân Tích Dữ Liệu là Gì?
Multi-Agent Systems (MAS) trong nghiên cứu và phân tích dữ liệu là một kiến trúc phần mềm nơi nhiều tác nhân AI (agents) độc lập hoặc bán độc lập tương tác với nhau và với môi trường để hoàn thành một nhiệm vụ hoặc tập hợp các nhiệm vụ phức tạp. Mỗi agent có thể có mục tiêu, khả năng và kiến thức riêng, nhưng chúng cùng nhau đạt được một mục tiêu chung lớn hơn mà một agent đơn lẻ khó có thể thực hiện.

Hãy hình dung một đội ngũ chuyên gia ảo, nơi mỗi chuyên gia (agent) đảm nhiệm một vai trò cụ thể: một agent chuyên thu thập dữ liệu, một agent khác chuyên làm sạch và tiền xử lý, một agent phân tích thống kê, và một agent cuối cùng tổng hợp kết quả và đưa ra báo cáo. Sự phân chia công việc này giúp tối ưu hóa hiệu suất và độ chính xác. Theo một nghiên cứu của IBM vào năm 2023, việc áp dụng MAS có thể giảm tới 60% thời gian cần thiết cho các quy trình nghiên cứu dữ liệu lặp đi lặp lại so với phương pháp thủ công.
Các agent này có thể giao tiếp thông qua các giao thức định sẵn, chia sẻ thông tin, và thậm chí học hỏi kinh nghiệm từ các agent khác để cải thiện hiệu suất của toàn hệ thống. Điều này tạo ra một vòng lặp phản hồi tích cực, nơi đội quân AI ngày càng trở nên thông minh và hiệu quả hơn. Ví dụ, một agent phân tích dữ liệu có thể yêu cầu agent thu thập dữ liệu tìm kiếm thêm thông tin ở một khu vực cụ thể nếu phát hiện ra thiếu sót trong dữ liệu ban đầu. Sự linh hoạt và khả năng thích ứng này là chìa khóa cho sự thành công của multi-agent research trong các lĩnh vực động như tài chính, y tế hoặc thị trường.
MAS không chỉ đơn thuần là tự động hóa các bước riêng lẻ mà còn là tối ưu hóa toàn bộ quy trình làm việc thông qua sự phối hợp thông minh. Một hệ thống MAS hiệu quả có thể xử lý hàng terabyte dữ liệu mỗi ngày, đưa ra các insight mà con người có thể mất hàng tuần để tìm ra. Dữ liệu từ một báo cáo của Deloitte năm 2024 cho thấy, các công ty áp dụng MAS cho phân tích dữ liệu đã cải thiện 35% khả năng ra quyết định dựa trên dữ liệu.
Xây Dựng Đội Quân AI Agent: Hướng Dẫn Thực Hành
Để xây dựng một đội quân AI Agent, chúng ta cần xác định vai trò của từng agent, cơ chế giao tiếp và cách chúng phối hợp để hoàn thành nhiệm vụ. Chúng ta sẽ tập trung vào một ví dụ cụ thể: tự động hóa quy trình nghiên cứu thị trường cho một sản phẩm mới.
Quá trình này thường bao gồm các bước: thu thập thông tin đối thủ cạnh tranh, phân tích xu hướng thị trường, tổng hợp phản hồi khách hàng, và cuối cùng là tạo báo cáo tổng hợp. Với MAS, chúng ta có thể tạo ra các agent chuyên biệt cho từng bước:
- Data Collector Agent: Chuyên trách thu thập dữ liệu từ các nguồn khác nhau (web scraping, API, cơ sở dữ liệu).
- Data Cleaner Agent: Đảm bảo dữ liệu sạch sẽ, loại bỏ nhiễu, xử lý giá trị thiếu.
- Market Analyst Agent: Phân tích xu hướng, đối thủ, điểm mạnh/yếu của sản phẩm.
- Report Generator Agent: Tổng hợp kết quả, tạo báo cáo và biểu đồ trực quan.
Chúng ta có thể sử dụng các thư viện như CrewAI, LangChain, hoặc AutoGen để orchestrate các agent này. Đây là một ví dụ đơn giản về cách định nghĩa một agent bằng Python, sử dụng một framework giả định:
from agent_framework import Agent, Task, Environment
# Định nghĩa Data Collector Agent
class DataCollectorAgent(Agent):
def __init__(self, name):
super().__init__(name, role="Thu thập dữ liệu thị trường")
self.tools = ["web_scraper", "api_connector"]
def execute_task(self, task: Task):
print(f"Agent {self.name} đang thực hiện nhiệm vụ: {task.description}")
# Giả lập quá trình thu thập dữ liệu
collected_data = self.use_tool("web_scraper", task.parameters.get("query"))
# Gửi dữ liệu đã thu thập đến Data Cleaner Agent
self.environment.send_message("data_cleaner", {"raw_data": collected_data})
return {"status": "success", "data_count": len(collected_data)}
# Định nghĩa Data Cleaner Agent
class DataCleanerAgent(Agent):
def __init__(self, name):
super().__init__(name, role="Làm sạch và tiền xử lý dữ liệu")
self.tools = ["data_cleaning_library"]
def execute_task(self, task: Task):
print(f"Agent {self.name} đang thực hiện nhiệm vụ: {task.description}")
raw_data = task.parameters.get("raw_data")
cleaned_data = self.use_tool("data_cleaning_library", raw_data)
# Gửi dữ liệu đã làm sạch đến Market Analyst Agent
self.environment.send_message("market_analyst", {"cleaned_data": cleaned_data})
return {"status": "success", "cleaned_records": len(cleaned_data)}
# Khởi tạo môi trường và các agent
env = Environment()
collector = DataCollectorAgent("Collector")
cleaner = DataCleanerAgent("Cleaner")
env.add_agent(collector)
env.add_agent(cleaner)
# Giao nhiệm vụ ban đầu cho Collector Agent
initial_task = Task(description="Tìm kiếm 5 đối thủ cạnh tranh hàng đầu", parameters={"query": "top 5 competitors"})
collector.execute_task(initial_task)
Trong ví dụ trên, mỗi agent có một vai trò và bộ công cụ riêng. Agent giao tiếp qua môi trường chung, truyền dữ liệu và kết quả công việc cho nhau. Điều này cho phép một quy trình làm việc không bị gián đoạn, nơi các tác vụ được xử lý tuần tự hoặc song song. Để mở rộng quy mô, chúng ta có thể thêm các agent phức tạp hơn, chẳng hạn như một SentimentAnalysisAgent để phân tích cảm xúc từ các bài đánh giá sản phẩm hoặc một PredictiveModelingAgent để dự đoán xu hướng tương lai.
Việc triển khai thực tế một hệ thống như vậy đòi hỏi sự hiểu biết về kiến trúc phần mềm, quản lý trạng thái, và xử lý lỗi. Tuy nhiên, với các framework hiện đại, việc xây dựng các hệ thống multi-agent research đã trở nên dễ tiếp cận hơn rất nhiều. Các tổ chức đã báo cáo giảm 40-50% chi phí vận hành cho các tác vụ phân tích dữ liệu lặp lại sau khi triển khai các hệ thống MAS.
Để hệ thống hoạt động trơn tru, việc thiết kế cơ chế giao tiếp là tối quan trọng. Các agent có thể sử dụng các hàng đợi tin nhắn (message queues) như Kafka hoặc RabbitMQ, hoặc các giao thức RPC (Remote Procedure Call) để trao đổi thông tin. Sự lựa chọn phụ thuộc vào quy mô, độ trễ yêu cầu và kiến trúc tổng thể của hệ thống. Một điểm mạnh của MAS là khả năng mở rộng: bạn có thể thêm hoặc bớt agent tùy thuộc vào nhu cầu, mà không làm ảnh hưởng đến toàn bộ hệ thống.
# Ví dụ về một Market Analyst Agent với khả năng phối hợp phức tạp hơn
from agent_framework import Agent, Task, Environment
import pandas as pd
class MarketAnalystAgent(Agent):
def __init__(self, name):
super().__init__(name, role="Phân tích thị trường và đối thủ")
self.tools = ["statistical_analyzer", "trend_predictor"]
self.data_store = {} # Lưu trữ dữ liệu nhận được
def execute_task(self, task: Task):
print(f"Agent {self.name} đang thực hiện nhiệm vụ: {task.description}")
cleaned_data = task.parameters.get("cleaned_data")
self.data_store["market_data"] = cleaned_data
if "competitor_data" in self.data_store:
# Nếu đã có đủ dữ liệu, tiến hành phân tích
analysis_results = self._perform_analysis()
self.environment.send_message("report_generator", {"analysis_results": analysis_results})
return {"status": "success", "message": "Phân tích hoàn tất."}
else:
# Yêu cầu thêm dữ liệu nếu chưa đủ
print(f"Agent {self.name} đang chờ dữ liệu đối thủ từ Collector.")
# Gửi yêu cầu ngược lại
self.environment.send_message("data_collector", {"action": "collect_competitor_data", "query": "top competitor details"})
return {"status": "pending", "message": "Đang chờ dữ liệu bổ sung."}
def _perform_analysis(self):
# Giả lập phân tích dữ liệu
df = pd.DataFrame(self.data_store["market_data"])
# Thực hiện phân tích thống kê, dự đoán xu hướng
market_trends = self.use_tool("statistical_analyzer", df)
competitor_analysis = self.use_tool("trend_predictor", self.data_store["competitor_data"])
return {"trends": market_trends, "competitors": competitor_analysis}
# Khởi tạo và kết nối các agent trong một môi trường phức tạp hơn
env = Environment()
collector = DataCollectorAgent("Collector")
cleaner = DataCleanerAgent("Cleaner")
analyst = MarketAnalystAgent("Analyst")
# Thêm ReportGeneratorAgent tương tự
env.add_agent(collector)
env.add_agent(cleaner)
env.add_agent(analyst)
# Giả lập luồng dữ liệu
# 1. Collector thu thập dữ liệu thị trường
collector_task = Task(description="Thu thập dữ liệu thị trường chung", parameters={"query": "market overview"})
collector.execute_task(collector_task) # Giả sử gửi dữ liệu đến Cleaner
# 2. Cleaner xử lý và gửi đến Analyst
# Trong thực tế, Cleaner sẽ tự động gửi khi nhận được dữ liệu. Ở đây mô phỏng bằng cách gọi thủ công.
cleaned_market_data = [{"item": "A", "value": 10}, {"item": "B", "value": 20}] # Dữ liệu giả lập sau làm sạch
analyst_task_market = Task(description="Phân tích dữ liệu thị trường đã làm sạch", parameters={"cleaned_data": cleaned_market_data})
analyst.execute_task(analyst_task_market) # Analyst nhận dữ liệu thị trường
# 3. Collector thu thập dữ liệu đối thủ (có thể được yêu cầu bởi Analyst)
competitor_data_task = Task(description="Thu thập dữ liệu đối thủ", parameters={"query": "competitor X financials"})
collector.execute_task(competitor_data_task) # Giả sử gửi dữ liệu đến Cleaner
# 4. Cleaner xử lý dữ liệu đối thủ và gửi đến Analyst
cleaned_competitor_data = [{"competitor": "X", "revenue": 100}, {"competitor": "Y", "revenue": 120}] # Dữ liệu giả lập
analyst.data_store["competitor_data"] = cleaned_competitor_data # Analyst nhận dữ liệu đối thủ trực tiếp để đơn giản hóa
# 5. Analyst thực hiện phân tích tổng hợp khi có đủ dữ liệu
final_analysis_task = Task(description="Hoàn tất phân tích thị trường và đối thủ", parameters={})
analyst.execute_task(final_analysis_task)
Tips và Best Practices Khi Triển Khai Multi-Agent Research
Việc triển khai các hệ thống multi-agent research đòi hỏi sự chú ý đến nhiều yếu tố để đảm bảo hiệu quả và độ tin cậy.

- Xác định rõ ràng vai trò và trách nhiệm của từng Agent: Mỗi agent nên có một mục đích duy nhất và rõ ràng. Tránh việc một agent ôm đồm quá nhiều chức năng, điều này có thể dẫn đến sự phức tạp và khó bảo trì. Ví dụ, một
DataFetcherAgentchỉ nên tập trung vào việc lấy dữ liệu, không nên kiêm nhiệm việc làm sạch dữ liệu. - Thiết kế cơ chế giao tiếp mạnh mẽ: Agent cần có khả năng giao tiếp hiệu quả, trao đổi thông tin và yêu cầu tác vụ. Sử dụng các giao thức tin nhắn chuẩn hoặc hàng đợi tin nhắn để đảm bảo tính nhất quán và khả năng mở rộng. Ví dụ, sử dụng JSON hoặc Protocol Buffers làm định dạng dữ liệu cho các tin nhắn.
- Đảm bảo tính độc lập và khả năng chịu lỗi: Các agent nên hoạt động độc lập nhất có thể. Nếu một agent gặp lỗi, các agent khác vẫn có thể tiếp tục hoạt động hoặc tự động tìm cách khắc phục. Triển khai cơ chế retry và fallback để tăng cường tính ổn định của hệ thống.
- Tối ưu hóa tài nguyên: Theo dõi việc sử dụng tài nguyên (CPU, RAM, network) của từng agent để tránh tắc nghẽn và đảm bảo hiệu suất. Sử dụng các công cụ giám sát để nhận diện các điểm nóng và tối ưu hóa khi cần thiết. Một nghiên cứu của Google cho thấy, việc tối ưu hóa tài nguyên có thể giảm 20% chi phí vận hành cho các hệ thống phân tích dữ liệu quy mô lớn.
- Thiết kế vòng lặp phản hồi và học hỏi: Cho phép các agent học hỏi từ kết quả của các agent khác hoặc từ môi trường. Điều này có thể thông qua các mô hình học máy tăng cường (reinforcement learning) hoặc các quy tắc heuristic được cập nhật động. Ví dụ, một
RecommendationAgentcó thể điều chỉnh chiến lược dựa trên phản hồi về độ chính xác của các khuyến nghị trước đó. - Thử nghiệm và lặp lại liên tục: Giống như bất kỳ hệ thống phần mềm phức tạp nào, MAS cần được thử nghiệm kỹ lưỡng trong các kịch bản khác nhau. Thu thập phản hồi, phân tích hiệu suất và lặp lại thiết kế để cải thiện.
- Bảo mật dữ liệu và quyền riêng tư: Khi làm việc với dữ liệu nhạy cảm, đảm bảo rằng các agent tuân thủ các quy định về bảo mật và quyền riêng tư (ví dụ: GDPR, HIPAA). Mã hóa dữ liệu khi truyền tải và lưu trữ, và giới hạn quyền truy cập của từng agent chỉ ở mức cần thiết.
So Sánh Multi-Agent Systems với Các Phương Pháp Phân Tích Dữ Liệu Khác
Multi-Agent Systems (MAS) mang lại những lợi thế đáng kể so với các phương pháp phân tích dữ liệu truyền thống và thậm chí cả các hệ thống AI đơn lẻ, đặc biệt trong các tác vụ multi-agent research phức tạp.
So với phân tích dữ liệu thủ công: MAS vượt trội về tốc độ, khả năng mở rộng và độ chính xác. Một nhóm nhà khoa học dữ liệu có thể mất nhiều ngày để thu thập và làm sạch dữ liệu, trong khi một hệ thống MAS có thể hoàn thành trong vài giờ. MAS giảm thiểu lỗi do con người gây ra và đảm bảo tính nhất quán trong quy trình. Tuy nhiên, phân tích thủ công vẫn quan trọng cho các vấn đề đòi hỏi sự sáng tạo, suy luận sâu sắc mà AI chưa thể làm được.
So với hệ thống AI đơn lẻ (Monolithic AI): Hệ thống AI đơn lẻ, dù mạnh mẽ đến đâu, thường gặp khó khăn khi đối mặt với các vấn đề đa diện đòi hỏi nhiều loại chuyên môn. Ví dụ, một mô hình phân tích ngôn ngữ tự nhiên (NLP) có thể rất giỏi trong việc hiểu văn bản, nhưng nó cần tích hợp thêm các module khác để thu thập văn bản từ web, làm sạch nó, và sau đó trực quan hóa kết quả. MAS giải quyết vấn đề này bằng cách phân chia trách nhiệm cho các agent chuyên biệt, mỗi agent tối ưu cho một nhiệm vụ cụ thể. Điều này giúp hệ thống dễ phát triển, bảo trì và mở rộng hơn. Nếu một phần của hệ thống cần được nâng cấp (ví dụ: thuật toán làm sạch dữ liệu), chỉ cần cập nhật agent tương ứng mà không ảnh hưởng đến toàn bộ hệ thống.
So với các pipelines ETL (Extract, Transform, Load) truyền thống: Pipelines ETL rất hiệu quả cho các quy trình dữ liệu có cấu trúc và cố định. Tuy nhiên, chúng thường cứng nhắc và kém linh hoạt khi dữ liệu hoặc yêu cầu phân tích thay đổi. MAS, với khả năng ra quyết định tự chủ và giao tiếp của các agent, có thể thích ứng tốt hơn với các môi trường động. Ví dụ, nếu một nguồn dữ liệu đột ngột thay đổi định dạng, một DataCollectorAgent thông minh có thể tự động điều chỉnh hoặc thông báo cho các agent khác về sự thay đổi, điều mà một pipeline ETL tĩnh sẽ gặp khó khăn. MAS cũng có thể xử lý các tác vụ phi tuyến tính hoặc đòi hỏi suy luận phức tạp hơn ETL.
Tóm lại, nếu bạn cần một hệ thống có khả năng tự động hóa các quy trình dữ liệu phức tạp, cần sự phối hợp giữa nhiều chuyên môn, và cần khả năng thích ứng cao với sự thay đổi, thì MAS là lựa chọn vượt trội. Một cuộc khảo sát của Gartner năm 2023 chỉ ra rằng, 70% doanh nghiệp đang tìm kiếm các giải pháp tự động hóa thông minh như MAS để cải thiện quy trình phân tích dữ liệu của họ.
Các Lưu Ý Quan Trọng
- Phức tạp trong Thiết kế và Triển khai: Mặc dù mạnh mẽ, việc thiết kế và triển khai một hệ thống MAS đòi hỏi kiến thức sâu rộng về kiến trúc phần mềm, lập trình đồng thời và xử lý phân tán. Sự phối hợp giữa các agent có thể tạo ra các vấn đề phức tạp như deadlock hoặc race condition nếu không được quản lý cẩn thận.
- Chi phí Phát triển ban đầu: Chi phí đầu tư ban đầu cho việc xây dựng và cấu hình các agent, cũng như cơ sở hạ tầng để chúng giao tiếp, có thể cao hơn so với các giải pháp đơn giản hơn. Tuy nhiên, khoản đầu tư này thường được bù đắp bởi hiệu quả và khả năng mở rộng về lâu dài.
- Quản lý và Giám sát: Khi số lượng agent tăng lên, việc quản lý và giám sát hoạt động của chúng trở nên khó khăn hơn. Cần có các công cụ giám sát tập trung để theo dõi hiệu suất, phát hiện lỗi và đảm bảo các agent đang hoạt động như mong đợi.
- Khả năng Giải thích (Explainability): Với sự tương tác phức tạp giữa nhiều agent, việc hiểu tại sao hệ thống đưa ra một quyết định cụ thể có thể là một thách thức. Điều này đặc biệt quan trọng trong các lĩnh vực yêu cầu tính minh bạch cao như y tế hoặc tài chính. Cần thiết kế các cơ chế ghi nhật ký (logging) và truy vết (tracing) để tăng cường khả năng giải thích.
- Vấn đề Đồng bộ hóa và Nhất quán Dữ liệu: Khi nhiều agent cùng truy cập và sửa đổi dữ liệu, việc đảm bảo tính đồng bộ và nhất quán của dữ liệu là rất quan trọng. Cần sử dụng các cơ chế khóa (locking), giao dịch (transactions) hoặc các mô hình dữ liệu bất biến để tránh xung đột.
- Chọn Framework phù hợp: Việc lựa chọn framework (như LangChain, CrewAI, AutoGen) có thể ảnh hưởng lớn đến quá trình phát triển. Mỗi framework có ưu nhược điểm riêng về tính năng, cộng đồng hỗ trợ và độ phức tạp. Hãy nghiên cứu kỹ để chọn công cụ phù hợp nhất với nhu cầu dự án của bạn cho multi-agent research.
Câu Hỏi Thường Gặp
Multi-Agent Systems có phù hợp cho các doanh nghiệp nhỏ không?
Có, Multi-Agent Systems có thể phù hợp cho các doanh nghiệp nhỏ, đặc biệt nếu họ có nhu cầu tự động hóa các tác vụ nghiên cứu và phân tích dữ liệu lặp đi lặp lại. Mặc dù chi phí phát triển ban đầu có thể là một rào cản, nhưng với sự phát triển của các framework mã nguồn mở và các nền tảng AI dễ sử dụng, việc triển khai MAS đã trở nên dễ tiếp cận hơn. Các doanh nghiệp nhỏ có thể bắt đầu với các hệ thống đơn giản, tập trung vào một số tác vụ cụ thể để tối ưu hóa chi phí và hiệu quả. Ví dụ, một hệ thống gồm 2-3 agent có thể tự động hóa việc thu thập thông tin đối thủ cạnh tranh và phân tích cảm xúc khách hàng, tiết kiệm hàng giờ làm việc mỗi tuần.
Làm thế nào để đảm bảo các agent giao tiếp hiệu quả?
Để đảm bảo các agent giao tiếp hiệu quả, cần thiết kế một giao thức giao tiếp rõ ràng và nhất quán. Điều này bao gồm việc định nghĩa cấu trúc tin nhắn (ví dụ: JSON hoặc XML), các kênh giao tiếp (hàng đợi tin nhắn, API RESTful), và các quy tắc về thời điểm và cách thức các agent gửi/nhận tin nhắn. Sử dụng một trung gian giao tiếp tập trung (như một Message Broker) có thể giúp quản lý luồng tin nhắn và xử lý lỗi tốt hơn. Ngoài ra, việc sử dụng các ngôn ngữ giao tiếp agent (ACL - Agent Communication Language) như FIPA ACL có thể chuẩn hóa quá trình trao đổi thông tin, giúp các agent hiểu nhau tốt hơn.
Multi-Agent Systems có thể tự học và cải thiện hiệu suất không?
Có, Multi-Agent Systems có khả năng tự học và cải thiện hiệu suất, đặc biệt khi được tích hợp với các kỹ thuật học máy. Các agent có thể học hỏi từ kinh nghiệm của chính mình (ví dụ: điều chỉnh tham số dựa trên kết quả trước đó), từ môi trường (ví dụ: thích ứng với sự thay đổi của dữ liệu), hoặc từ các agent khác (ví dụ: chia sẻ kiến thức hoặc mô hình học được). Việc sử dụng học tăng cường (Reinforcement Learning) cho phép các agent tối ưu hóa hành vi của mình để đạt được mục tiêu chung của hệ thống. Một ví dụ điển hình là các agent trong hệ thống giao dịch chứng khoán có thể học cách tối ưu hóa chiến lược mua bán dựa trên dữ liệu thị trường theo thời gian thực.
Kết Luận
Xây dựng đội quân AI Agent thông qua Multi-Agent Systems là một bước tiến đột phá trong việc tự động hóa và nâng cao hiệu quả của quy trình nghiên cứu và phân tích dữ liệu. Bằng cách phân chia các nhiệm vụ phức tạp thành các vai trò chuyên biệt cho từng agent, chúng ta có thể tối ưu hóa từng khía cạnh của quy trình, từ thu thập dữ liệu đến tạo báo cáo. Điều này không chỉ giúp tiết kiệm thời gian và nguồn lực mà còn nâng cao độ chính xác và khả năng thích ứng của hệ thống.
Mặc dù có những thách thức trong thiết kế và triển khai, tiềm năng mà multi-agent research mang lại là rất lớn. Với sự phát triển không ngừng của các framework và công nghệ AI, việc xây dựng các hệ thống thông minh, tự động hóa toàn diện đang trở nên hiện thực hơn bao giờ hết. Hãy bắt đầu khám phá và ứng dụng sức mạnh của các hệ thống đa tác nhân để biến những ý tưởng nghiên cứu phức tạp thành hiện thực một cách thần tốc. Nếu bạn đang tìm kiếm những giải pháp công nghệ tiên tiến và muốn cập nhật những xu hướng mới nhất trong lĩnh vực AI, hãy ghé thăm vibe coding để tìm hiểu thêm.