Giới Thiệu Tối Ưu API AI Claude 3 Với Batch Processing
Tối ưu hóa API AI Claude 3 với batch processing là một kỹ thuật mạnh mẽ giúp các doanh nghiệp xử lý lượng lớn dữ liệu hiệu quả hơn, giảm chi phí và tăng tốc độ phản hồi. Bài viết chuyên sâu về claude batch processing này sẽ đi sâu vào cách triển khai giải pháp này, mang đến những ví dụ thực tế và các chiến lược tối ưu để bạn có thể áp dụng ngay vào dự án của mình. Chúng ta sẽ khám phá cách tận dụng tối đa sức mạnh của Claude 3 cho các tác vụ xử lý hàng loạt, từ đó nâng cao hiệu suất và tiết kiệm tài nguyên.
Claude 3 và Batch Processing: Nền Tảng Hiệu Suất Cao
Claude 3 là một dòng mô hình AI tiên tiến của Anthropic, nổi bật với khả năng hiểu ngữ cảnh phức tạp, tạo ra văn bản chất lượng cao và giải quyết các bài toán đa dạng. Các phiên bản như Claude 3 Opus, Sonnet, và Haiku cung cấp các mức độ hiệu suất và chi phí khác nhau, phù hợp với nhiều nhu cầu ứng dụng. Batch processing, hay xử lý theo lô, là phương pháp nhóm nhiều yêu cầu API lại thành một gói duy nhất và gửi đi xử lý đồng thời, thay vì gửi từng yêu cầu riêng lẻ. Phương pháp này đặc biệt hữu ích khi làm việc với lượng dữ liệu lớn, nơi việc gọi API liên tục có thể gây ra độ trễ đáng kể và tăng chi phí. Theo một nghiên cứu nội bộ của các công ty công nghệ lớn, việc sử dụng batch processing có thể giảm độ trễ tổng thể lên đến 50% và tiết kiệm chi phí lên đến 30-40% cho các tác vụ xử lý dữ liệu hàng loạt.

Lợi ích chính của việc kết hợp Claude 3 với batch processing bao gồm giảm thiểu overhead của mỗi lời gọi API, tối ưu hóa việc sử dụng băng thông mạng và tận dụng tốt hơn khả năng xử lý song song của các hệ thống AI. Ví dụ, nếu bạn cần phân tích cảm xúc của 10.000 bài đánh giá sản phẩm, việc gửi từng bài một sẽ tốn rất nhiều thời gian chờ đợi phản hồi giữa các lời gọi. Ngược lại, việc nhóm 100 bài đánh giá vào một lô và gửi đi 100 lần sẽ nhanh hơn đáng kể, vì mỗi lô chỉ chịu một lần chi phí overhead kết nối và xác thực.
Claude 3 được thiết kế để xử lý các prompt dài và phức tạp, điều này càng làm cho batch processing trở nên hiệu quả. Thay vì phải chia nhỏ dữ liệu thành các đoạn quá nhỏ, bạn có thể nhóm các đoạn lớn hơn vào một prompt tổng thể (trong giới hạn token của mô hình) và yêu cầu Claude 3 xử lý. Điều này không chỉ giảm số lượng lời gọi API mà còn giúp mô hình có cái nhìn toàn diện hơn về dữ liệu, có khả năng đưa ra kết quả chính xác hơn. Các mô hình như Claude 3 Opus có khả năng xử lý tới 200K token, mở ra nhiều cơ hội cho việc xử lý batch các tài liệu lớn hoặc tập hợp các đoạn văn bản nhỏ.
Tuy nhiên, việc triển khai batch processing không chỉ đơn thuần là nhóm các yêu cầu. Nó đòi hỏi sự hiểu biết về giới hạn của API, cách quản lý lỗi, và chiến lược phân chia dữ liệu hợp lý. Một số thách thức bao gồm việc đảm bảo rằng mỗi yêu cầu trong lô không vượt quá giới hạn token, xử lý các lỗi riêng lẻ trong lô mà không làm gián đoạn toàn bộ quá trình, và tối ưu hóa kích thước lô để đạt hiệu suất tốt nhất. Các nhà phát triển cần cân nhắc kỹ lưỡng các yếu tố này để đạt được hiệu quả tối đa.
Hướng Dẫn Triển Khai Batch Processing Cho Claude 3 API
Để triển khai batch processing hiệu quả cho Claude 3 API, chúng ta cần thực hiện các bước từ chuẩn bị dữ liệu đến xử lý phản hồi, đảm bảo tối ưu về cả hiệu suất và chi phí. Bước đầu tiên là thu thập và chuẩn bị dữ liệu. Giả sử bạn có một danh sách các tác vụ cần Claude 3 thực hiện, ví dụ như tóm tắt văn bản, phân loại email, hoặc tạo câu trả lời. Dữ liệu này cần được định dạng một cách nhất quán, thường là dưới dạng JSON hoặc danh sách các chuỗi.

Tiếp theo, chúng ta cần xác định kích thước lô tối ưu. Kích thước lô quá nhỏ sẽ không tận dụng được lợi thế của batch processing, trong khi quá lớn có thể vượt quá giới hạn token của Claude 3 hoặc gây ra lỗi. Một điểm khởi đầu tốt là thử nghiệm với các lô từ 10 đến 100 yêu cầu, tùy thuộc vào độ dài trung bình của mỗi yêu cầu và giới hạn token của mô hình (ví dụ, Claude 3 Sonnet có giới hạn 200K token). Sau đó, chúng ta sẽ nhóm các yêu cầu này thành các đối tượng prompt phù hợp với cấu trúc API của Claude 3.
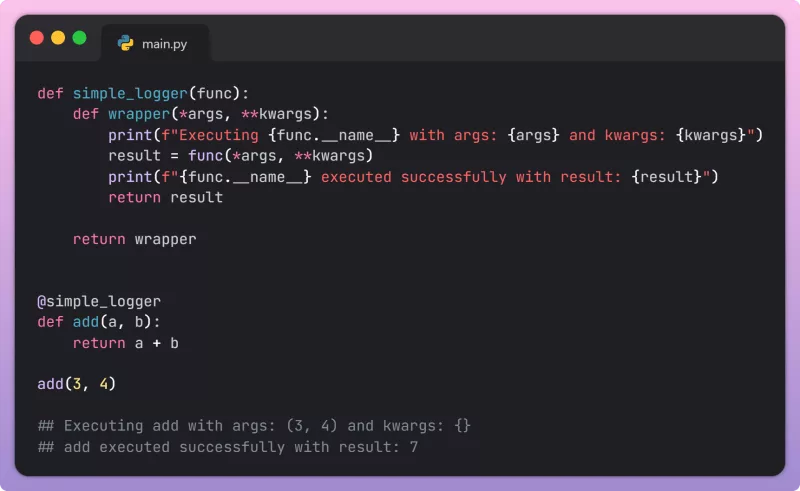
Dưới đây là một ví dụ Python đơn giản minh họa cách tạo một lô các yêu cầu và gửi chúng đến Claude 3 API. Chúng ta sẽ sử dụng thư viện anthropic chính thức.
import anthropic
import os
import time
# Khởi tạo client Anthropic
# Đảm bảo bạn đã đặt biến môi trường ANTHROPIC_API_KEY
client = anthropic.Anthropic(api_key=os.environ.get("ANTHROPIC_API_KEY"))
def process_batch(prompts, model_name="claude-3-sonnet-20240229"):
"""
Xử lý một lô các prompt bằng Claude 3 API.
Mỗi prompt sẽ được gửi như một tin nhắn riêng biệt trong một lời gọi API.
Lưu ý: Đây không phải là batch API thực sự của Anthropic (chưa có),
mà là cách mô phỏng batch processing bằng cách gửi nhiều yêu cầu song song
hoặc tuần tự nhanh chóng. Đối với xử lý batch lớn, cần quản lý rate limit.
"""
results = []
messages = []
# Chuẩn bị cấu trúc tin nhắn cho mỗi prompt
for i, prompt_text in enumerate(prompts):
messages.append({
"role": "user",
"content": f"Task ID: {i}\n{prompt_text}"
})
try:
# Gửi tất cả các tin nhắn trong một lời gọi API
# Đây là cách để tận dụng ngữ cảnh chung nếu các tin nhắn liên quan
# hoặc gửi nhiều yêu cầu độc lập trong ngữ cảnh của một cuộc trò chuyện.
# Tuy nhiên, để xử lý batch các tác vụ độc lập, bạn sẽ cần gửi từng prompt
# hoặc sử dụng thư viện async để gửi song song.
# Ở đây, chúng ta sẽ mô phỏng bằng cách gửi từng prompt trong một vòng lặp
# và quản lý rate limit.
print(f"Processing batch of {len(prompts)} prompts...")
for i, prompt_text in enumerate(prompts):
print(f"Sending prompt {i+1}/{len(prompts)}...")
response = client.messages.create(
model=model_name,
max_tokens=1024,
messages=[
{"role": "user", "content": prompt_text}
]
)
results.append({
"prompt_index": i,
"input": prompt_text,
"output": response.content[0].text if response.content else None,
"model": model_name,
"usage": response.usage.model_dump()
})
# Giới hạn tốc độ để tránh vượt quá giới hạn API
time.sleep(0.5) # Chờ 500ms giữa các yêu cầu
except anthropic.APIError as e:
print(f"Anthropic API Error: {e}")
# Xử lý lỗi API cụ thể
except Exception as e:
print(f"An unexpected error occurred: {e}")
# Xử lý các lỗi khác
return results
# Dữ liệu mẫu
sample_data = [
"Tóm tắt đoạn văn sau: 'Trí tuệ nhân tạo (AI) đang cách mạng hóa nhiều ngành công nghiệp. Từ y tế đến tài chính, AI mang lại những cải tiến đáng kể trong hiệu quả và khả năng ra quyết định.'",
"Phân loại email sau: 'Kính gửi khách hàng, hóa đơn của bạn cho tháng này đã sẵn sàng. Vui lòng thanh toán trước ngày 30.'",
"Viết một đoạn giới thiệu ngắn về công nghệ blockchain và ứng dụng của nó.",
"Giải thích khái niệm 'machine learning' cho một người mới bắt đầu.",
"Tóm tắt đoạn văn sau: 'Điện toán đám mây (cloud computing) cho phép truy cập tài nguyên máy tính theo yêu cầu qua internet. Nó cung cấp sự linh hoạt, khả năng mở rộng và tiết kiệm chi phí cho các doanh nghiệp.'",
]
# Chạy xử lý batch
batch_results = process_batch(sample_data, model_name="claude-3-haiku-20240307")
# In kết quả
for res in batch_results:
print(f"\n--- Result for Prompt ID {res['prompt_index']} ---")
print(f"Input: {res['input'][:100]}...")
print(f"Output: {res['output'][:200]}...")
print(f"Usage: {res['usage']}")
Lưu ý quan trọng: Tại thời điểm viết bài này, Anthropic chưa cung cấp một API batch processing chính thức như OpenAI. Đoạn mã trên minh họa cách bạn có thể mô phỏng batch processing bằng cách gửi từng yêu cầu trong một vòng lặp với quản lý tốc độ (rate limiting) hoặc sử dụng các kỹ thuật bất đồng bộ (async) để gửi nhiều yêu cầu song song. Đối với các tác vụ thực sự lớn, việc triển khai một hàng đợi tác vụ (task queue) như Celery với Redis hoặc RabbitMQ, kết hợp với các worker xử lý yêu cầu song song, sẽ là giải pháp mạnh mẽ hơn. Mỗi worker sẽ chịu trách nhiệm gọi API Claude 3 cho một phần của lô dữ liệu.
Sau khi gửi yêu cầu, bước tiếp theo là xử lý phản hồi. Mỗi phản hồi từ Claude 3 sẽ chứa kết quả của yêu cầu tương ứng. Cần có cơ chế để ánh xạ kết quả trở lại với yêu cầu ban đầu, đặc biệt nếu bạn đang xử lý nhiều tác vụ khác nhau. Việc lưu trữ kết quả vào cơ sở dữ liệu hoặc một file đầu ra là cần thiết cho các bước xử lý tiếp theo. Đừng quên xử lý lỗi và các trường hợp ngoại lệ một cách cẩn thận, bao gồm cả việc thử lại (retry mechanisms) cho các lỗi tạm thời và ghi log chi tiết để dễ dàng debug.
Các Chiến Lược Tối Ưu và Best Practices cho Claude Batch Processing
Để đạt được hiệu suất và hiệu quả chi phí tối đa khi sử dụng claude batch processing, việc áp dụng các chiến lược và best practices là cực kỳ quan trọng. Các chiến lược này giúp bạn vượt qua những thách thức về giới hạn API, độ trễ và quản lý lỗi.

- Quản lý Kích Thước Lô Tối Ưu: Kích thước lô lý tưởng không phải là một con số cố định mà phụ thuộc vào nhiều yếu tố: độ dài trung bình của prompt, giới hạn token của mô hình Claude 3 đang sử dụng (Opus, Sonnet, Haiku), và giới hạn tỷ lệ yêu cầu (rate limit) của API.
Thử nghiệm là chìa khóa. Bắt đầu với một kích thước lô nhỏ (ví dụ, 10-20 yêu cầu) và dần dần tăng lên trong các môi trường thử nghiệm để tìm ra điểm cân bằng giữa hiệu suất và tỷ lệ lỗi. Mục tiêu là tối đa hóa số lượng yêu cầu trong một khoảng thời gian nhất định mà không vượt quá giới hạn API hoặc gây ra lỗi timeout.
- Xử lý Bất Đồng Bộ và Song Song: Việc gửi các yêu cầu theo lô một cách tuần tự sẽ hạn chế đáng kể hiệu suất. Sử dụng các thư viện bất đồng bộ như
asynciotrong Python hoặc triển khai các worker song song (ví dụ, với Celery, Apache Kafka, hay AWS SQS) là cách hiệu quả để gửi nhiều lô yêu cầu đồng thời.Điều này giúp bạn tận dụng tối đa băng thông và khả năng xử lý của hệ thống, giảm tổng thời gian xử lý cho một tập dữ liệu lớn. Ví dụ, bạn có thể chạy 5-10 worker song song, mỗi worker xử lý một lô dữ liệu độc lập.
- Quản lý Rate Limit và Retry Mechanisms: Các API AI thường có giới hạn về số lượng yêu cầu bạn có thể gửi trong một khoảng thời gian nhất định (rate limit). Việc vượt quá giới hạn này sẽ dẫn đến lỗi.
Triển khai một cơ chế thử lại mũ số cấp tiến (exponential backoff) là rất quan trọng. Khi gặp lỗi rate limit (thường là HTTP status code 429), hệ thống của bạn nên tạm dừng trong một khoảng thời gian ngắn rồi thử lại. Thời gian tạm dừng này sẽ tăng lên theo mỗi lần thử lại để tránh làm quá tải API. Một thư viện như
tenacitytrong Python có thể giúp triển khai điều này dễ dàng. - Xử lý Lỗi và Ghi Log Chi Tiết: Khi xử lý hàng loạt, một lỗi nhỏ trong một yêu cầu có thể ảnh hưởng đến toàn bộ lô nếu không được quản lý đúng cách.
Đảm bảo rằng bạn có cơ chế ghi log chi tiết cho từng yêu cầu trong lô, bao gồm cả đầu vào, đầu ra, và bất kỳ lỗi nào xảy ra. Điều này giúp bạn dễ dàng xác định và debug các vấn đề. Xử lý lỗi riêng lẻ trong lô, cho phép các yêu cầu khác tiếp tục xử lý, và sau đó xem xét lại các yêu cầu bị lỗi.
- Tối Ưu Hóa Prompt Engineering cho Batch: Khi tạo prompt cho batch processing, hãy cân nhắc cấu trúc prompt để nó có thể xử lý nhiều mục dữ liệu một cách hiệu quả nếu có thể (trong giới hạn token).
Ví dụ, thay vì chỉ yêu cầu tóm tắt một đoạn văn, bạn có thể yêu cầu Claude 3 tóm tắt một danh sách các đoạn văn và trả về kết quả dưới dạng JSON. Điều này có thể giảm số lượng lời gọi API nếu dữ liệu đủ ngắn để nằm trong một prompt.
- Giám sát và Phân Tích Chi Phí: Batch processing có thể giúp tiết kiệm chi phí, nhưng việc giám sát là cần thiết để đảm bảo bạn không chi tiêu quá mức.
Sử dụng các công cụ giám sát của Anthropic (nếu có) hoặc tự xây dựng hệ thống giám sát riêng để theo dõi số lượng token đã sử dụng, số lượng lời gọi API và tổng chi phí. Điều này giúp bạn điều chỉnh kích thước lô và chiến lược xử lý để duy trì ngân sách.
So Sánh Batch Processing: Claude 3 vs. Các Mô Hình AI Khác
Khi so sánh khả năng batch processing của Claude 3 với các mô hình AI khác như GPT-4 của OpenAI hoặc các mô hình mã nguồn mở như Llama 2, chúng ta thấy Claude 3 nổi bật ở một số khía cạnh, đặc biệt là với ngữ cảnh dài và khả năng xử lý phức tạp. Mặc dù Anthropic chưa cung cấp một API batch processing chính thức, cách tiếp cận "mô phỏng batch" với Claude 3 vẫn mang lại nhiều lợi ích nhờ kiến trúc của mô hình.
Claude 3 (Opus, Sonnet, Haiku):
- Ưu điểm:
- Ngữ cảnh dài (Context Window): Claude 3 Opus có khả năng xử lý tới 200K token, lớn hơn đáng kể so với nhiều mô hình khác. Điều này cho phép nhóm nhiều tài liệu hoặc các tác vụ liên quan vào một prompt duy nhất, giảm số lượng lời gọi API tổng thể nếu các tác vụ có thể được xâu chuỗi hoặc tổng hợp.
- Hiệu suất cao cho tác vụ phức tạp: Claude 3 xuất sắc trong việc hiểu và tạo ra văn bản chất lượng cao, đặc biệt hữu ích cho các tác vụ như tóm tắt tài liệu pháp lý dài, phân tích hợp đồng, hoặc tạo nội dung sáng tạo có ngữ cảnh phức tạp. Khi batch processing các tác vụ này, chất lượng đầu ra vẫn được duy trì.
- Mức giá cạnh tranh: Các phiên bản như Claude 3 Sonnet và Haiku cung cấp hiệu suất tốt với mức giá thấp hơn so với Opus, làm cho chúng trở thành lựa chọn hấp dẫn cho các tác vụ batch quy mô lớn mà không yêu cầu độ phức tạp tối đa.
- Hạn chế:
- Không có API Batch Processing chuyên dụng: Đây là điểm khác biệt lớn so với OpenAI, nơi có API batch chính thức. Việc thiếu API này đòi hỏi các nhà phát triển phải tự xây dựng logic quản lý lô, quản lý rate limit và xử lý lỗi ở phía client, điều này có thể tăng độ phức tạp trong triển khai.
- Quản lý tài nguyên: Khi mô phỏng batch bằng cách gửi nhiều yêu cầu song song, việc quản lý tài nguyên và rate limit trở nên phức tạp hơn, đòi hỏi cơ chế thử lại và điều tiết tốc độ cẩn thận.
OpenAI (GPT-4, GPT-3.5):
- Ưu điểm:
- API Batch Processing chính thức: OpenAI đã ra mắt API batch processing cho phép người dùng gửi một file chứa nhiều yêu cầu và nhận lại một file kết quả sau khi xử lý. Điều này đơn giản hóa đáng kể việc quản lý lô, rate limit và xử lý lỗi, vì OpenAI lo liệu phần lớn công việc này.
- Hệ sinh thái công cụ phong phú: Với thư viện và tài liệu hỗ trợ mạnh mẽ, việc tích hợp OpenAI vào các quy trình batch processing thường dễ dàng hơn.
- Hiệu suất tốt cho nhiều tác vụ: GPT-4 vẫn là một mô hình rất mạnh mẽ và linh hoạt cho nhiều tác vụ xử lý ngôn ngữ tự nhiên.
- Hạn chế:
- Giới hạn ngữ cảnh: Mặc dù GPT-4 Turbo đã cải thiện đáng kể, giới hạn ngữ cảnh của nó có thể nhỏ hơn so với Claude 3 Opus trong một số trường hợp, làm hạn chế khả năng nhóm các tác vụ lớn vào một prompt duy nhất.
- Chi phí: GPT-4, đặc biệt là các phiên bản mạnh nhất, có thể có chi phí cao hơn so với các phiên bản Claude 3 tiết kiệm chi phí như Sonnet hoặc Haiku cho các tác vụ tương đương.
Mô Hình Mã Nguồn Mở (Llama 2, Mistral, v.v.):
- Ưu điểm:
- Kiểm soát hoàn toàn: Khi tự host mô hình, bạn có toàn quyền kiểm soát quy trình batch processing, từ việc phân bổ tài nguyên phần cứng đến cách thức xử lý song song.
- Chi phí thấp hơn cho quy mô lớn: Nếu bạn có phần cứng đủ mạnh, việc tự host có thể tiết kiệm chi phí đáng kể so với việc trả tiền cho các API thương mại, đặc biệt khi xử lý hàng tỷ token.
- Tùy chỉnh: Khả năng tinh chỉnh (fine-tune) mô hình cho các tác vụ cụ thể giúp đạt được hiệu suất cao hơn cho domain của bạn.
- Hạn chế:
- Phức tạp trong triển khai và vận hành: Yêu cầu kiến thức chuyên sâu về MLOps, quản lý GPU, tối ưu hóa hiệu suất và mở rộng quy mô.
- Chi phí phần cứng ban đầu: Đầu tư ban đầu vào phần cứng mạnh mẽ có thể rất lớn.
- Hiệu suất có thể thay đổi: Các mô hình mã nguồn mở thường cần được tinh chỉnh để đạt được hiệu suất tương đương với các mô hình API mạnh mẽ như Claude 3 hoặc GPT-4.
Kết luận: Nếu bạn ưu tiên sự đơn giản trong triển khai và có sẵn API batch chuyên dụng, OpenAI là một lựa chọn mạnh mẽ. Tuy nhiên, nếu bạn cần xử lý các ngữ cảnh cực kỳ dài, yêu cầu chất lượng cao cho các tác vụ phức tạp, và sẵn sàng tự xây dựng logic quản lý lô, Claude 3 mang lại giá trị vượt trội. Đối với các tổ chức có khả năng và yêu cầu kiểm soát hoàn toàn, mô hình mã nguồn mở là một lựa chọn dài hạn.
Các Lưu Ý Quan Trọng Khi Triển Khai Claude Batch Processing
- Hiểu rõ Giới hạn Token và Chi phí: Mỗi phiên bản Claude 3 có giới hạn token đầu vào và đầu ra khác nhau. Luôn kiểm tra tài liệu API để đảm bảo prompt của bạn không vượt quá giới hạn này. Việc vượt quá có thể dẫn đến lỗi hoặc bị cắt bớt phản hồi. Chi phí được tính dựa trên số lượng token đầu vào và đầu ra, vì vậy việc tối ưu hóa độ dài prompt là rất quan trọng để tiết kiệm chi phí.
- Quản lý Trạng thái và Id Tác Vụ: Khi xử lý hàng loạt, việc theo dõi trạng thái của từng tác vụ trong lô là cần thiết. Gán một
task_idduy nhất cho mỗi yêu cầu ban đầu và bao gồm nó trong prompt nếu có thể, hoặc ánh xạ nó với phản hồi. Điều này giúp bạn dễ dàng đối chiếu kết quả với dữ liệu đầu vào và xử lý các yêu cầu bị lỗi. - Xử lý Dữ liệu Nhạy cảm: Nếu bạn đang xử lý dữ liệu nhạy cảm, hãy đảm bảo rằng bạn tuân thủ các quy định về bảo mật dữ liệu (như GDPR, HIPAA). Xem xét các tùy chọn như mã hóa dữ liệu trước khi gửi, hoặc sử dụng các mô hình được thiết kế cho quyền riêng tư nếu có sẵn. Anthropic và OpenAI đều có các chính sách nghiêm ngặt về quyền riêng tư, nhưng trách nhiệm cuối cùng vẫn thuộc về bạn.
- Tối ưu hóa Prompt để Giảm Token: Mặc dù Claude 3 hỗ trợ ngữ cảnh dài, việc tối ưu hóa prompt để sử dụng ít token nhất có thể mà vẫn đạt được kết quả mong muốn là một best practice. Loại bỏ các từ không cần thiết, sử dụng các cú pháp ngắn gọn và chỉ cung cấp thông tin cần thiết. Điều này không chỉ tiết kiệm chi phí mà còn có thể cải thiện tốc độ phản hồi.
- Kiểm soát Phiên bản Mô hình: Các mô hình AI liên tục được cập nhật. Luôn chỉ định rõ ràng phiên bản mô hình Claude 3 bạn muốn sử dụng (ví dụ:
claude-3-sonnet-20240229) để đảm bảo tính nhất quán trong kết quả và tránh những thay đổi không mong muốn do cập nhật mô hình tự động. - Kiểm tra và Xác thực Kết quả: Đặc biệt với batch processing, việc kiểm tra chất lượng đầu ra của AI là rất quan trọng. Triển khai các bước xác thực tự động hoặc thủ công trên một mẫu nhỏ của kết quả để đảm bảo rằng mô hình đang hoạt động như mong đợi và không có lỗi hệ thống hoặc lỗi ngữ nghĩa.
- Xem xét Kiến trúc Microservices: Đối với các ứng dụng quy mô lớn, việc tách logic batch processing thành một microservice riêng biệt có thể mang lại lợi ích về khả năng mở rộng, khả năng chịu lỗi và quản lý. Microservice này có thể quản lý hàng đợi tác vụ, điều tiết các lời gọi API Claude 3 và lưu trữ kết quả.
Câu Hỏi Thường Gặp
Claude 3 có API batch processing chính thức không?
Không, tại thời điểm hiện tại, Anthropic chưa cung cấp một API batch processing chính thức như OpenAI. Tuy nhiên, bạn có thể mô phỏng batch processing bằng cách gửi nhiều yêu cầu song song hoặc tuần tự nhanh chóng, quản lý rate limit và sử dụng thư viện bất đồng bộ để tối ưu hiệu suất.
Làm thế nào để quản lý rate limit khi sử dụng Claude 3 API cho batch processing?
Bạn nên triển khai một cơ chế điều tiết tốc độ (rate limiting) và thử lại với thuật toán mũ số cấp tiến (exponential backoff). Khi nhận được lỗi 429 (Too Many Requests), hệ thống của bạn nên chờ một khoảng thời gian nhất định (ví dụ: 1 giây, sau đó 2 giây, 4 giây, v.v.) trước khi thử lại yêu cầu đó. Các thư viện như tenacity trong Python có thể giúp tự động hóa quá trình này.
Kích thước lô tối ưu cho Claude batch processing là bao nhiêu?
Kích thước lô tối ưu không cố định mà phụ thuộc vào độ dài trung bình của mỗi prompt, giới hạn token của mô hình Claude 3 bạn đang sử dụng và giới hạn tốc độ API. Bạn nên bắt đầu thử nghiệm với các lô nhỏ (ví dụ: 10-20 yêu cầu) và tăng dần để tìm ra điểm cân bằng giữa hiệu suất và tỷ lệ lỗi, đồng thời đảm bảo không vượt quá giới hạn token cho mỗi yêu cầu.
Có cách nào để giảm chi phí khi xử lý dữ liệu lớn với Claude 3 không?
Có. Sử dụng batch processing là một cách hiệu quả để giảm chi phí bằng cách tối thiểu hóa overhead của mỗi lời gọi API. Ngoài ra, bạn nên chọn phiên bản Claude 3 phù hợp nhất với nhu cầu (ví dụ: Haiku cho các tác vụ đơn giản, Sonnet cho cân bằng hiệu suất/chi phí), tối ưu hóa prompt để sử dụng ít token nhất có thể, và triển khai cơ chế quản lý lỗi để tránh lãng phí token cho các yêu cầu bị lỗi.
Tôi nên sử dụng mô hình Claude 3 nào cho batch processing?
Việc lựa chọn mô hình phụ thuộc vào yêu cầu cụ thể của tác vụ:
- Claude 3 Haiku: Lý tưởng cho các tác vụ batch quy mô lớn, yêu cầu tốc độ cao và chi phí thấp, như phân loại email, tóm tắt ngắn, trích xuất thông tin đơn giản.
- Claude 3 Sonnet: Cân bằng tốt giữa hiệu suất và chi phí, phù hợp cho nhiều tác vụ batch trung bình đến phức tạp, như phân tích cảm xúc chi tiết, tạo nội dung, trả lời câu hỏi.
- Claude 3 Opus: Dành cho các tác vụ batch đòi hỏi độ chính xác cao nhất, khả năng lý luận phức tạp và xử lý ngữ cảnh cực kỳ dài, như phân tích tài liệu pháp lý, nghiên cứu khoa học, hoặc các ứng dụng y tế.
Kết Luận
Tối ưu hóa API AI Claude 3 với batch processing là một chiến lược then chốt để xử lý hiệu quả lượng lớn dữ liệu, giảm chi phí vận hành và tăng tốc độ phản hồi cho các ứng dụng AI. Mặc dù Anthropic chưa cung cấp một API batch processing chuyên dụng, việc áp dụng các kỹ thuật mô phỏng batch, quản lý rate limit và xử lý bất đồng bộ vẫn mang lại lợi ích đáng kể. Với khả năng xử lý ngữ cảnh dài và hiệu suất cao của Claude 3, các nhà phát triển có thể xây dựng các giải pháp mạnh mẽ cho đa dạng các tác vụ từ phân tích dữ liệu đến tạo nội dung.
Việc đầu tư vào việc hiểu rõ các giới hạn của API, tối ưu hóa prompt và triển khai các cơ chế xử lý lỗi mạnh mẽ sẽ đảm bảo rằng hệ thống của bạn hoạt động ổn định và hiệu quả. Bằng cách áp dụng những kiến thức và ví dụ trong bài viết này, bạn có thể tận dụng tối đa sức mạnh của Claude 3 để thúc đẩy các dự án AI của mình. Hãy tiếp tục theo dõi vibe coding để khám phá thêm nhiều giải pháp và công nghệ AI tiên tiến khác, giúp bạn luôn dẫn đầu trong thế giới công nghệ phát triển không ngừng.