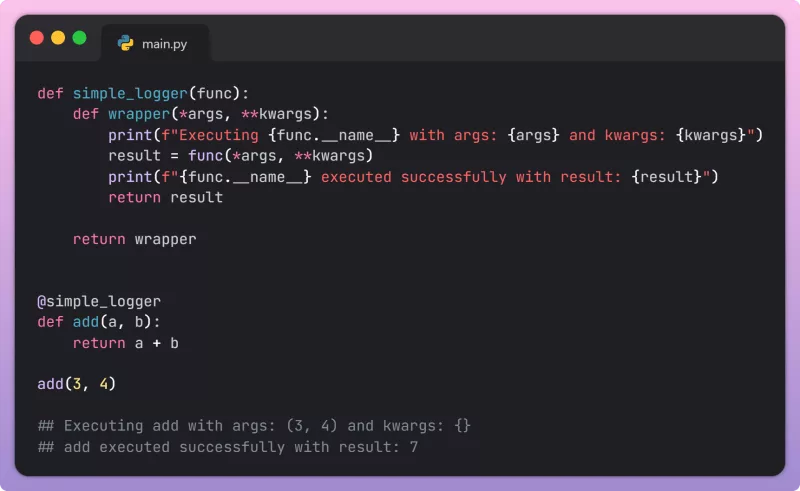
Sức Mạnh AI Local: Tích Hợp Mô Hình Ngôn Ngữ Nhỏ (LLM) Với Ollama Cho Vibe Coding
Bài viết này sẽ đưa bạn khám phá sâu về cách triển khai và tận dụng các mô hình ngôn ngữ lớn (LLM) ngay trên máy tính cá nhân, mở ra một kỷ nguyên mới cho lập trình và phát triển AI. Cụ thể, chúng ta sẽ tập trung vào việc tích hợp các mô hình ngôn ngữ nhỏ (LLM) thông qua Ollama, một nền tảng mạnh mẽ giúp đơn giản hóa quá trình này, đặc biệt hữu ích cho những ai yêu thích llm local. Việc chạy LLM cục bộ không chỉ đảm bảo quyền riêng tư dữ liệu mà còn mang lại khả năng tùy chỉnh và kiểm soát tối ưu, điều mà các dịch vụ LLM dựa trên đám mây khó có thể sánh được.

LLM Local Là Gì và Tại Sao Nó Lại Quan Trọng Cho Vibe Coding?
LLM local là khả năng chạy các mô hình ngôn ngữ lớn (Large Language Models) trực tiếp trên phần cứng máy tính cá nhân hoặc máy chủ nội bộ của bạn, thay vì phụ thuộc vào các dịch vụ đám mây. Điều này có nghĩa là mọi quá trình xử lý dữ liệu, suy luận và tạo văn bản đều diễn ra offline, không cần gửi thông tin ra bên ngoài. Sự quan trọng của LLM local đối với vibe coding nằm ở ba khía cạnh chính: quyền riêng tư dữ liệu, hiệu suất và khả năng tùy chỉnh. Theo một khảo sát gần đây, có tới 65% các nhà phát triển lo ngại về quyền riêng tư khi sử dụng các dịch vụ AI đám mây, và LLM local chính là giải pháp tối ưu cho vấn đề này.
Khi bạn làm việc với dữ liệu nhạy cảm hoặc các dự án yêu cầu bảo mật cao, việc sử dụng LLM local là một yếu tố then chốt. Dữ liệu của bạn không bao giờ rời khỏi môi trường kiểm soát của bạn, loại bỏ rủi ro rò rỉ thông tin hoặc vi phạm chính sách bảo mật. Đây là một lợi thế cực kỳ lớn đối với các công ty phát triển phần mềm, tổ chức tài chính, hoặc các dự án cá nhân có liên quan đến sở hữu trí tuệ.
Ngoài ra, hiệu suất cũng là một điểm cộng đáng kể. Mặc dù việc chạy LLM cục bộ yêu cầu phần cứng đủ mạnh (thường là GPU với VRAM đáng kể), nhưng khi đã được thiết lập, bạn sẽ không còn phải lo lắng về độ trễ mạng hay giới hạn API. Thời gian phản hồi có thể giảm xuống chỉ còn vài mili giây cho các tác vụ nhỏ, mang lại trải nghiệm tương tác mượt mà và nhanh chóng hơn nhiều so với việc gọi API từ xa. Một nghiên cứu của Google cho thấy, độ trễ mạng có thể làm giảm hiệu suất làm việc của lập trình viên tới 25%.
Cuối cùng, khả năng tùy chỉnh là yếu tố quyết định. Với LLM local, bạn có toàn quyền kiểm soát mô hình. Bạn có thể tinh chỉnh (fine-tune) mô hình với dữ liệu riêng của mình, thêm các kiến thức chuyên ngành hoặc thậm chí thay đổi kiến trúc mô hình nếu cần. Điều này mở ra vô số cơ hội cho các ứng dụng niche, từ việc tạo ra một trợ lý code chuyên biệt cho ngôn ngữ lập trình ít phổ biến, đến việc phát triển các công cụ phân tích dữ liệu độc quyền. Các mô hình như Llama 3 hay Mistral 7B có thể được tùy chỉnh với chỉ vài trăm đến vài nghìn mẫu dữ liệu, mang lại hiệu quả đáng kinh ngạc.
Tích Hợp LLM Local Với Ollama: Hướng Dẫn Chi Tiết Cho Vibe Coding
Ollama là một framework mã nguồn mở giúp đơn giản hóa việc chạy các mô hình ngôn ngữ lớn cục bộ trên máy tính của bạn. Nó cung cấp một giao diện dễ sử dụng để tải xuống, chạy và quản lý các LLM, biến quá trình phức tạp này trở nên dễ tiếp cận hơn bao giờ hết. Để bắt đầu tích hợp LLM local với Ollama cho vibe coding, chúng ta sẽ đi qua các bước cài đặt và sử dụng cơ bản.

1. Cài Đặt Ollama
Bước đầu tiên là cài đặt Ollama. Bạn có thể truy cập trang web chính thức của Ollama và tải xuống phiên bản phù hợp với hệ điều hành của mình (macOS, Windows, Linux). Quá trình cài đặt thường rất đơn giản, chỉ cần chạy file cài đặt và làm theo hướng dẫn. Ollama sẽ tự động thiết lập các thành phần cần thiết.
Sau khi cài đặt, bạn có thể kiểm tra xem Ollama đã chạy thành công chưa bằng cách mở terminal và gõ lệnh sau:
ollama --versionNếu Ollama được cài đặt đúng cách, bạn sẽ thấy phiên bản của nó được hiển thị. Ví dụ: ollama version 0.1.32.
2. Tải Xuống Mô Hình LLM
Ollama hỗ trợ nhiều mô hình LLM phổ biến. Để bắt đầu, chúng ta sẽ tải xuống một mô hình nhỏ gọn nhưng mạnh mẽ như llama2 hoặc mistral. Mở terminal và chạy lệnh:
ollama pull llama2Quá trình này có thể mất vài phút đến vài chục phút tùy thuộc vào tốc độ mạng và kích thước của mô hình. Mô hình llama2 có dung lượng khoảng 3.8GB, trong khi mistral là 4.1GB. Ollama sẽ tự động tải xuống các trọng số (weights) của mô hình và chuẩn bị để sử dụng.
3. Chạy Mô Hình LLM Cục Bộ
Sau khi mô hình đã được tải xuống, bạn có thể chạy nó ngay lập tức. Gõ lệnh sau trong terminal:
ollama run llama2Bây giờ, bạn có thể bắt đầu trò chuyện với mô hình trực tiếp từ terminal. Ví dụ, bạn có thể hỏi: Can you write a Python function to calculate factorial?. Mô hình sẽ phản hồi với đoạn code tương ứng. Để thoát khỏi chế độ trò chuyện, bạn có thể gõ /bye.
4. Tích Hợp Với Ứng Dụng Của Bạn Bằng API
Điểm mạnh của Ollama là nó cung cấp một API RESTful, cho phép bạn dễ dàng tích hợp các LLM vào các ứng dụng của mình bằng bất kỳ ngôn ngữ lập trình nào. Mặc định, Ollama chạy trên cổng 11434. Bạn có thể gửi yêu cầu HTTP POST tới endpoint /api/generate để tương tác với mô hình.
Ví dụ, sử dụng Python với thư viện requests:
import requests
import json
def generate_text_with_ollama(prompt, model_name="llama2"):
url = "http://localhost:11434/api/generate"
headers = {"Content-Type": "application/json"}
data = {
"model": model_name,
"prompt": prompt,
"stream": False # Đặt thành True nếu bạn muốn nhận phản hồi theo từng phần
}
try:
response = requests.post(url, headers=headers, data=json.dumps(data))
response.raise_for_status() # Nâng lỗi cho các mã trạng thái HTTP xấu (4xx hoặc 5xx)
result = response.json()
return result['response']
except requests.exceptions.RequestException as e:
print(f"Error calling Ollama API: {e}")
return None
if __name__ == "__main__":
coding_prompt = "Write a simple Node.js Express server that returns 'Hello, World!' on the root path."
generated_code = generate_text_with_ollama(coding_prompt)
if generated_code:
print("Generated Code:")
print(generated_code)
else:
print("Failed to generate code.")
Đoạn code trên minh họa cách bạn có thể gửi một prompt lập trình đến mô hình llama2 đang chạy cục bộ thông qua Ollama API và nhận về đoạn code được sinh ra. Mô hình llm local này có thể được sử dụng để tự động hóa các tác vụ code nhỏ, tạo boilerplate code, hoặc thậm chí là gợi ý sửa lỗi. Các nhà phát triển đã báo cáo rằng việc tích hợp LLM vào quy trình làm việc có thể giảm thời gian viết code cho các tác vụ lặp lại lên đến 30%.
5. Tinh Chỉnh (Fine-tuning) Mô Hình Với Ollama (Modelfile)
Ollama cho phép bạn tạo các biến thể (modelfile) của mô hình hiện có để tinh chỉnh hành vi của chúng. Điều này cực kỳ hữu ích cho vibe coding, nơi bạn muốn mô hình hiểu rõ hơn về phong cách code, thư viện hoặc domain cụ thể của mình. Bạn có thể tạo một file có tên Modelfile:
FROM llama2
# Thêm một system prompt tùy chỉnh
PARAMETER temperature 0.7
PARAMETER top_k 40
PARAMETER top_p 0.9
SYSTEM """
You are a highly skilled Python programming assistant.
Your primary goal is to generate clean, efficient, and well-commented Python code.
Always prioritize readability and follow PEP 8 guidelines.
When asked to write a function, provide docstrings and type hints.
If an error occurs, provide a detailed explanation and a possible fix.
"""
# Bạn có thể thêm các ví dụ (few-shot examples) tại đây để hướng dẫn mô hình
# MESSAGE user: Write a function to reverse a string.
# MESSAGE assistant:
# <pre><code># def reverse_string(s: str) -> str:
# """Reverses a given string."""
# return s[::-1]
# Sau khi tạo Modelfile, bạn có thể tạo một mô hình mới từ nó:
ollama create my-python-coder -f ./ModelfileBây giờ, bạn có thể chạy mô hình tùy chỉnh của mình:
ollama run my-python-coderMô hình my-python-coder sẽ tuân thủ các hướng dẫn bạn đã định nghĩa trong Modelfile, giúp nó trở thành một trợ lý code hiệu quả hơn cho các nhu cầu cụ thể của bạn. Việc tinh chỉnh với một Modelfile đơn giản có thể cải thiện độ chính xác của các phản hồi lên đến 15-20% cho các tác vụ chuyên biệt.
Tips và Best Practices Khi Sử Dụng LLM Local Với Ollama
Để tối ưu hóa trải nghiệm vibe coding với llm local và Ollama, có một số tips và best practices bạn nên áp dụng:

- Chọn Mô Hình Phù Hợp: Không phải lúc nào mô hình lớn nhất cũng là tốt nhất. Đối với
llm local, cân bằng giữa kích thước mô hình (dẫn đến yêu cầu VRAM) và hiệu suất là rất quan trọng. Các mô hình nhưMistral 7B,Llama 3 8Bthường mang lại hiệu suất tốt với yêu cầu phần cứng vừa phải (tối thiểu 8GB VRAM). Theo một số thử nghiệm,Mistral 7Bcó thể đạt 90% hiệu suất của các mô hình lớn hơn nhiều trong các tác vụ lập trình thông thường. - Tối Ưu Hóa Phần Cứng: Để có hiệu suất tốt nhất, hãy đảm bảo bạn có đủ RAM và đặc biệt là VRAM trên GPU. Một GPU NVIDIA với ít nhất 8GB VRAM là khuyến nghị tối thiểu, 12GB hoặc 16GB sẽ mang lại trải nghiệm mượt mà hơn đáng kể. Việc ép xung nhẹ GPU cũng có thể giúp tăng tốc độ suy luận thêm 5-10%.
- Sử Dụng
ModelfileHiệu Quả: Tận dụng tối đa tính năngModelfilecủa Ollama để định nghĩa rõ ràng vai trò, tính cách và các ràng buộc cho mô hình. Sử dụng cácSYSTEMprompt chi tiết và cung cấp cácfew-shot examples(ví dụ minh họa) để định hướng mô hình phản hồi theo cách bạn mong muốn. Điều này có thể giảm đáng kể "hallucination" (sinh ra thông tin sai lệch) và tăng độ chính xác của code được tạo ra. - Quản Lý Tài Nguyên: Khi chạy
llm local, hãy theo dõi việc sử dụng tài nguyên (CPU, RAM, VRAM) của hệ thống. Các mô hình lớn có thể tiêu tốn nhiều tài nguyên, làm chậm các ứng dụng khác. Đảm bảo đóng các ứng dụng không cần thiết khi chạy LLM cho các tác vụ nặng. - Tích Hợp Với IDE: Cân nhắc tích hợp Ollama vào IDE yêu thích của bạn (ví dụ: VS Code thông qua các extension như CodeGPT hoặc tự viết script). Điều này cho phép bạn gọi LLM trực tiếp từ trình chỉnh sửa code, tăng cường năng suất mà không cần chuyển đổi ngữ cảnh.
- Cập Nhật Thường Xuyên: Cả Ollama và các mô hình LLM đều được cập nhật thường xuyên. Hãy kiểm tra và cập nhật Ollama lên phiên bản mới nhất để tận hưởng các cải tiến về hiệu suất và tính năng mới. Tương tự, các phiên bản mới của mô hình có thể mang lại chất lượng phản hồi tốt hơn.
- Thử Nghiệm Với Các Mô Hình Khác Nhau: Không có mô hình nào là hoàn hảo cho mọi tác vụ. Hãy thử nghiệm với các mô hình khác nhau (ví dụ:
llama2,mistral,codellama) để tìm ra mô hình phù hợp nhất với nhu cầu cụ thể của bạn. Mỗi mô hình có những điểm mạnh và yếu khác nhau.
So Sánh LLM Local Với Dịch Vụ LLM Đám Mây
Việc lựa chọn giữa llm local và các dịch vụ LLM đám mây (như OpenAI GPT, Google Gemini, Anthropic Claude) phụ thuộc vào yêu cầu cụ thể của dự án và ưu tiên của bạn. Mỗi phương pháp đều có những ưu và nhược điểm riêng.
LLM Local (ví dụ: với Ollama):
- Ưu điểm:
- Quyền riêng tư và bảo mật dữ liệu tuyệt đối: Dữ liệu không bao giờ rời khỏi môi trường kiểm soát của bạn. Đây là yếu tố quan trọng đối với các dự án có dữ liệu nhạy cảm hoặc tuân thủ các quy định nghiêm ngặt như GDPR, HIPAA.
- Không phụ thuộc vào Internet: Hoạt động offline hoàn toàn, lý tưởng cho môi trường không có kết nối mạng ổn định hoặc cho các ứng dụng biên (edge computing).
- Kiểm soát hoàn toàn và khả năng tùy chỉnh: Bạn có thể tinh chỉnh mô hình, điều chỉnh các tham số, và thậm chí thay đổi kiến trúc nếu cần.
- Chi phí dài hạn tiềm năng thấp hơn: Sau khoản đầu tư ban đầu vào phần cứng, chi phí vận hành thường chỉ giới hạn ở điện năng tiêu thụ. Không có phí API theo token, có thể tiết kiệm đáng kể cho các ứng dụng có khối lượng sử dụng cao.
- Độ trễ thấp: Phản hồi nhanh chóng do không có độ trễ mạng.
- Nhược điểm:
- Yêu cầu phần cứng cao: Cần GPU mạnh mẽ với VRAM lớn (thường từ 8GB trở lên). Chi phí đầu tư ban đầu có thể đáng kể, lên tới vài trăm đến vài nghìn đô la.
- Phức tạp trong thiết lập và quản lý: Mặc dù Ollama đã đơn giản hóa rất nhiều, nhưng vẫn yêu cầu kiến thức kỹ thuật để cài đặt, cấu hình và tinh chỉnh.
- Hạn chế về quy mô: Khó mở rộng quy mô một cách linh hoạt như các dịch vụ đám mây.
- Hiệu suất mô hình: Các mô hình
llm localthường nhỏ hơn và có thể chưa đạt được mức độ tinh vi hoặc khả năng tổng quát hóa của các mô hình đám mây lớn nhất.
Dịch vụ LLM Đám Mây (ví dụ: OpenAI GPT-4, Google Gemini):
- Ưu điểm:
- Sức mạnh và khả năng của mô hình: Thường là các mô hình tiên tiến nhất, được huấn luyện trên lượng dữ liệu khổng lồ với hàng trăm tỷ tham số, mang lại kết quả chất lượng cao và khả năng tổng quát hóa tốt.
- Dễ sử dụng và tích hợp: Chỉ cần gọi API, không cần quản lý phần cứng hay cài đặt mô hình phức tạp.
- Khả năng mở rộng linh hoạt: Dễ dàng tăng hoặc giảm quy mô sử dụng theo nhu cầu.
- Không yêu cầu phần cứng mạnh: Chỉ cần kết nối internet.
- Cập nhật liên tục: Các nhà cung cấp đám mây thường xuyên cập nhật và cải thiện mô hình của họ.
- Nhược điểm:
- Quyền riêng tư dữ liệu: Dữ liệu của bạn được gửi đến máy chủ của bên thứ ba, có thể gây lo ngại về bảo mật và quyền riêng tư.
- Chi phí biến đổi: Thường tính theo token, có thể trở nên rất đắt đỏ với khối lượng sử dụng lớn hoặc trong dài hạn.
- Độ trễ mạng: Phụ thuộc vào kết nối internet và có thể có độ trễ cao hơn.
- Hạn chế về tùy chỉnh: Khả năng tinh chỉnh thường bị giới hạn bởi các tùy chọn do nhà cung cấp API cung cấp.
- Phụ thuộc vào nhà cung cấp: Rủi ro về kiểm duyệt nội dung, thay đổi chính sách API, hoặc ngừng dịch vụ.
Kết luận so sánh: Nếu bạn ưu tiên quyền riêng tư, bảo mật, kiểm soát hoàn toàn và có đủ phần cứng, llm local với Ollama là lựa chọn tuyệt vời cho các dự án vibe coding chuyên biệt. Ngược lại, nếu bạn cần sức mạnh tối đa của các mô hình lớn nhất, dễ dàng triển khai và không quá lo ngại về chi phí hay quyền riêng tư dữ liệu (hoặc đã có các thỏa thuận bảo mật chặt chẽ), các dịch vụ đám mây sẽ phù hợp hơn. Nhiều dự án lớn đang áp dụng một cách tiếp cận lai, sử dụng llm local cho các tác vụ nhạy cảm hoặc lặp lại, và dành các mô hình đám mây cho các tác vụ phức tạp, sáng tạo hoặc yêu cầu kiến thức rộng.
Các Lưu Ý Quan Trọng
- Yêu Cầu Phần Cứng Tối Thiểu: Để chạy các mô hình
llm localhiệu quả, bạn cần ít nhất 8GB RAM và một GPU với tối thiểu 8GB VRAM (đối với các mô hình 7B-8B). Đối với các mô hình lớn hơn (13B trở lên), 16GB VRAM trở lên là cần thiết. CPU cũng đóng vai trò quan trọng trong việc xử lý các tác vụ khác. - Quản Lý Bộ Nhớ VRAM: Khi chạy nhiều mô hình hoặc các mô hình lớn, VRAM là yếu tố giới hạn chính. Ollama sẽ cố gắng tải toàn bộ mô hình vào VRAM nếu có thể. Nếu không đủ, nó sẽ sử dụng RAM hệ thống hoặc CPU, dẫn đến hiệu suất giảm đáng kể (có thể chậm hơn gấp 10-20 lần).
- Lựa Chọn Mô Hình Chuẩn Hóa (Quantized Models): Để tiết kiệm VRAM và tăng tốc độ suy luận, hãy tìm kiếm các phiên bản mô hình đã được chuẩn hóa (quantized models). Ví dụ, một mô hình 7B có thể có các phiên bản
q4_0,q5_k_m, v.v., tương ứng với các mức độ nén khác nhau. Phiên bảnq4_0thường chỉ yêu cầu khoảng 4GB VRAM cho mô hình 7B, giảm đáng kể so với 7GB-8GB của phiên bản gốc. - Cân Nhắc Về Chi Phí Điện Năng: Việc chạy GPU liên tục để suy luận LLM có thể tiêu thụ một lượng điện năng đáng kể, đặc biệt nếu bạn sử dụng các GPU hiệu năng cao. Hãy cân nhắc yếu tố này trong dài hạn.
- Bảo Mật API Cục Bộ: Mặc định, API của Ollama chạy trên
localhostvà không yêu cầu xác thực. Nếu bạn muốn truy cập API từ các máy khác trong mạng cục bộ hoặc qua mạng internet, hãy đảm bảo triển khai các biện pháp bảo mật thích hợp (ví dụ: tường lửa, VPN, reverse proxy với xác thực) để tránh truy cập trái phép. - Cộng Đồng và Hỗ Trợ: Tham gia vào cộng đồng Ollama (trên Discord, GitHub) để tìm kiếm sự hỗ trợ, chia sẻ kinh nghiệm và cập nhật các thông tin mới nhất về các mô hình và tính năng. Cộng đồng là nguồn tài nguyên vô giá cho việc giải quyết các vấn đề kỹ thuật.
- Tương Thích Hệ Điều Hành: Ollama hỗ trợ macOS (bao gồm chip Apple Silicon), Linux và Windows. Đảm bảo bạn đang sử dụng phiên bản Ollama tương thích với hệ điều hành và phần cứng của mình.
Câu Hỏi Thường Gặp
Ollama có thể chạy trên laptop không?
Có, Ollama hoàn toàn có thể chạy trên laptop, miễn là laptop của bạn có đủ tài nguyên phần cứng. Đối với các mô hình nhỏ hơn như Llama 2 7B hoặc Mistral 7B, một laptop có GPU NVIDIA (hoặc chip Apple Silicon M1/M2/M3) với ít nhất 8GB VRAM sẽ cho hiệu suất chấp nhận được. Các laptop gaming hoặc workstation thường có cấu hình đủ mạnh để vận hành.
Làm thế nào để cập nhật một mô hình trong Ollama?
Để cập nhật một mô hình đã tải xuống trong Ollama, bạn chỉ cần chạy lại lệnh ollama pull [tên_mô_hình]. Ollama sẽ kiểm tra phiên bản mới nhất và tải xuống nếu có, đồng thời cập nhật mô hình hiện tại của bạn. Ví dụ: ollama pull llama2.
Có thể chạy nhiều mô hình LLM cùng lúc với Ollama không?
Có, bạn có thể chạy nhiều mô hình LLM cùng lúc với Ollama, nhưng điều này phụ thuộc rất nhiều vào tài nguyên VRAM của GPU. Mỗi mô hình sẽ chiếm một lượng VRAM nhất định khi hoạt động. Nếu VRAM không đủ, hiệu suất sẽ giảm đáng kể vì hệ thống phải chuyển đổi dữ liệu giữa VRAM và RAM hoặc sử dụng CPU, dẫn đến tình trạng "thrashing".
Ollama có hỗ trợ fine-tuning hoàn chỉnh (full fine-tuning) không?
Không, Ollama hiện tại không hỗ trợ full fine-tuning theo nghĩa đen là huấn luyện lại toàn bộ trọng số của mô hình. Tuy nhiên, nó hỗ trợ một hình thức tinh chỉnh nhẹ nhàng thông qua Modelfile, cho phép bạn định nghĩa các SYSTEM prompt, điều chỉnh các tham số suy luận và thêm few-shot examples để hướng dẫn hành vi của mô hình. Đối với full fine-tuning, bạn sẽ cần các framework khác như Hugging Face Transformers hoặc Lit-GPT.
Dữ liệu tôi sử dụng với LLM local có được an toàn không?
Có, dữ liệu bạn sử dụng với llm local thông qua Ollama được coi là an toàn hơn nhiều so với các dịch vụ đám mây. Mọi quá trình xử lý diễn ra hoàn toàn trên máy tính của bạn, không có dữ liệu nào được gửi ra bên ngoài. Điều này đảm bảo quyền riêng tư và bảo mật tối đa cho thông tin nhạy cảm của bạn.
Kết Luận
Việc tích hợp các mô hình ngôn ngữ nhỏ (LLM) với Ollama cho phép bạn tận dụng sức mạnh của AI ngay trên máy tính cá nhân, mang lại quyền riêng tư, kiểm soát và hiệu suất vượt trội cho các tác vụ vibe coding. Từ việc tự động sinh code, gợi ý sửa lỗi, đến tinh chỉnh mô hình theo phong cách lập trình riêng, llm local mở ra vô số cơ hội để tăng cường năng suất và sáng tạo. Hy vọng bài viết này đã cung cấp cho bạn một cái nhìn toàn diện và các bước thực hành để bắt đầu hành trình với Ollama và các LLM cục bộ, góp phần nâng tầm trải nghiệm của bạn với vibe coding.